Yes, code re-factoring really is as scary as it sounds.
Despite that, over at PadiAct we recently plunged into bringing the whole app code up to date: cleaned it, made it shiny and removed anything that shouldn’t be there, and on Monday we were all set to deploy the new, improved app.
I’ve often said that I co-created InnerTrends to scratch my own itch but in the lead up to and aftermath of refactoring, it saved me and the rest of the PadiAct team from total disaster. As we are often reminded on Seconds From Disaster, “disasters don’t just happen: they are a chain of critical events.”
Welcome to our own chain of critical events and the story of how InnerTrends helped us avoid a very unpleasant situation.
Critical Event #1: Rackspace reboot and our DNS settings went rogue
PadiAct is hosted on Rackspace and over the weekend they decided to perform an across the cloud reboot, one that they announced at the very last minute. Their CEO explained the reason for the unscheduled reboot and despite the inconvenience (more on that in a moment) I have to applaud their actions. Downtime is preferable to being hacked, every time.
During the reboot, the DNS settings of our servers were impacted and suddenly, in a random pattern, PadiAct was unable to contact critical 3rd party services it relies on. Being random, it was not something we could easily replicate. If it weren’t for InnerTrends, we would probably have ignored it and carried on with the deploy as planned.
Luckily we checked the error logbook that InnerTrends builds for our app and we realized it wasn’t going to be just another day at the office. The visual speaks for itself:
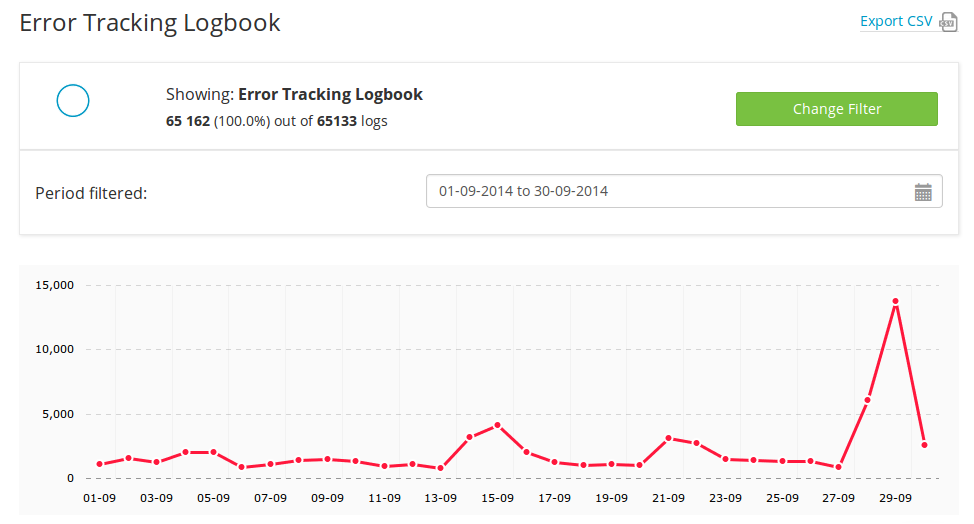
Critical Event #2: Security certificates went rogue
On Friday, a major security certificates update had been applied by our sys admin. Since we knew that a reboot was already scheduled by Rackspace, in a bid to keep downtime to a minimum, we decided not to do an additional reboot ourselves.
For reasons we can’t yet explain and are still investigating, the Rackspace reboot didn’t apply the new security update. We saw an error related to security certificates not being accepted by 3rd parties but at this stage we were blissfully unaware that the issue was with us, not them.
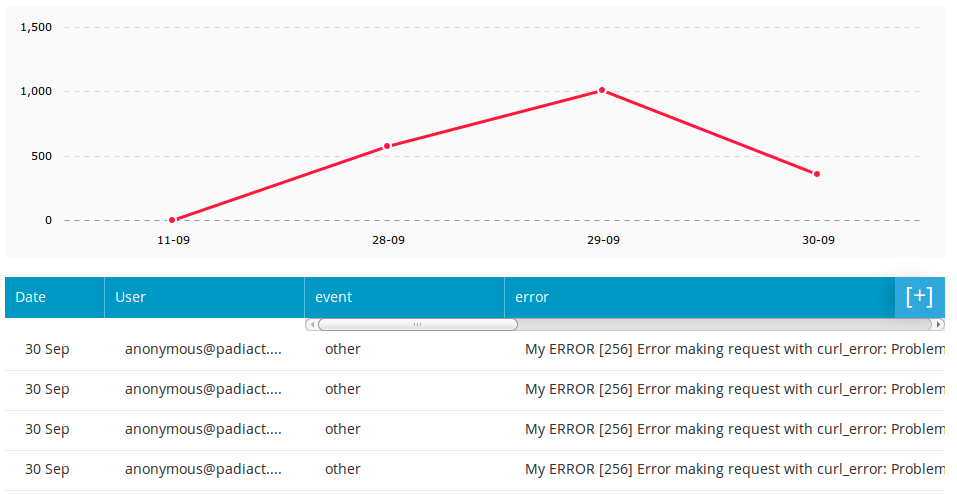
While we were trying to look into a possible fix for the errors, we decided to search for the specific error inside InnerTrends. Lucky for us that we did!
This error was not at all related to the issues that Rackspace had generated with their reboot. It was more painful than that. It was an error that negatively impacted the performance of our customer’s accounts.
Under normal (pre-InnerTrends) circumstances, these errors would probably have gone on undiscovered, until such time as a customer complained. That’s far too late for our liking. We much prefer to fix issues before our customers even suspect there might be a problem.
It was at this point that we decided to postpone the refactor deploy and I am so glad that we did! We wanted to be sure that we were doing it in as safe and controlled an environment as possible. If we’d gone ahead as planned on Monday, we would have spent the day chasing ghosts, blaming the refactor for our errors.
Critical Event 3: Refactor goes live
After the experiences of the previous few days, we decided to be prepared for this one! We tested everything for weeks on end in the lead up to the refactor but as is always the case, things go wrong. Thanks to InnerTrends though, we were able to quickly analyse issues in real time and fix them.
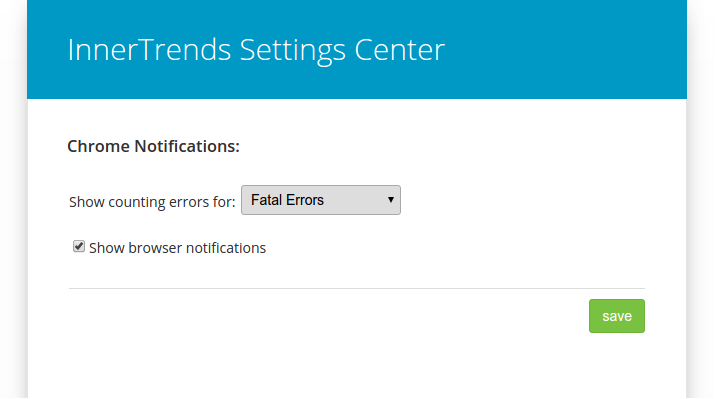
The errors we were most fearful of were fatal errors. The problem with fatal errors is that they are so fatal, the system can collapse and make the app unable to even notify InnerTrends about the issue.
In a bid to sidestep this flaw, we decided to write a script totally independent of our framework and platform that would run on the server every minute. Any time it found a fatal error in the logs it was programmed to send the error directly to InnerTrends.
With the script in place we started the deploy. To be absolutely sure that we would catch the fatal errors in time, we installed the new InnerTrends Chrome Plugin. It would notify us about any error logs we wanted it to, in real time, so we set it to notify us only about fatal errors.
While InnerTrends might say, “oops!”, we say, “Phew!”
Disaster avoided
The deploy is now live and our customers didn’t feel a thing and while things have been a little frenzied around here, they were a walk in the park compared to what would have happened if we’d released the deploy on Monday as scheduled.
It was thanks to InnerTrends that we were able to make informed business decisions, ones that resulted in a better experience for our customers, and a lot less stress for us!
Looking for deep insights into how your customers use your product?
InnerTrends can help. You won’t have to be a data scientist to discover the best growth opportunities for your business, our software will take care of that for you.
Schedule a Demo with us and witness with your own eyes just how powerful InnerTrends can be.